홈페이지에 누가 얼마나 왔다 갔는지 궁금하세요 ?
누가 어떤 경로로 왔는지 궁금하시죠 ?
Google 의 Analytics 는 최고의 홈페이지 방문 통계툴이다.
항상 느끼는 건데 구글은 정말 대단한 회사이다.
모든 회사들이 포탈이다 뭐다 하면서 복잡한 플래쉬에 이런 저런 정보로 도배를 했을 때에도 구글은
심플(simple)함 그 자체이다.
얼마나 단순 명료한가?
검색만 하는 사람은 딱 좋은 환경이다. 결과도 잘나오고 지저분하지 않고 빠르게 뜨기 때문에 구글은 최고의 검색엔진이다.
결국 구글은 포탈로 돈을 안벌고 검색엔진만으로 엄청난 광고 수입을 올리고 있다. 부럽다. 나도 이런거나 만들껄...
구글이 검색이 잘 되는 것은 홈페이지 정보를 정확하게 얻어내기 때문이다. 여기에 관련된 2가지 중요한 툴이 있다.
1) 구글 웹마스터 (webmaster)
웹마스터는 싸이트 내용을 효율적으로 수집하는 작업을 도와준다. 여기에 적절한 양식대로 등록하면 구글 검색엔진에서 검색이 더 잘된다. (구글봇의 크롤링이 효율적으로 된다.) 한마디로 내 홈페이지 여기 저기에 어떤 자료가 있으니 가져가세요라고 안내해주는 작업이라고 보면 된다.
2) 구글 어낼리틱스 (analytics)
홈페이지의 통계와 정보를 수집해 준다. 오늘의 주제다.
보통 홈페이지 방문 통계하면 카운터만 생각한다. 내 홈페이지도 3달전까지만 해도 카운터만 달았다. 우연히 웹서핑하다가 analytics 를 본 순간 탄성이 터졌다. 쵝오!!
Google Analytics 는 홈페이지 방문객의 많은 정보를 제공한다.
국가, 지도상의 위치, 새로 온사람인지 이전에 방문했던 사람인지, 몇번째 방문인지, 언어, 방문객수, 중복된 방문객을 제외한 방문객수, 한사람당 페이지를 얼마나 넘기고 가는지, 홈페이지에 몇분 있다가 나가는지, 홈페이지 들어왔다가 보지도 않고 바로 나가는지 아닌지 (Bounce rate), 브라우저는 어떤 것을 쓰는지, 운영체제는 리눅스인지 윈도우인지, 화면 해상도는 무엇인지, 어떤 검색엔진을 타고 들어왔는지, 어떤 키워드를 입력해서 방문했는지, 모뎀인지 고속인터넷인지 등등등
정말 많은 것을 제공한다.
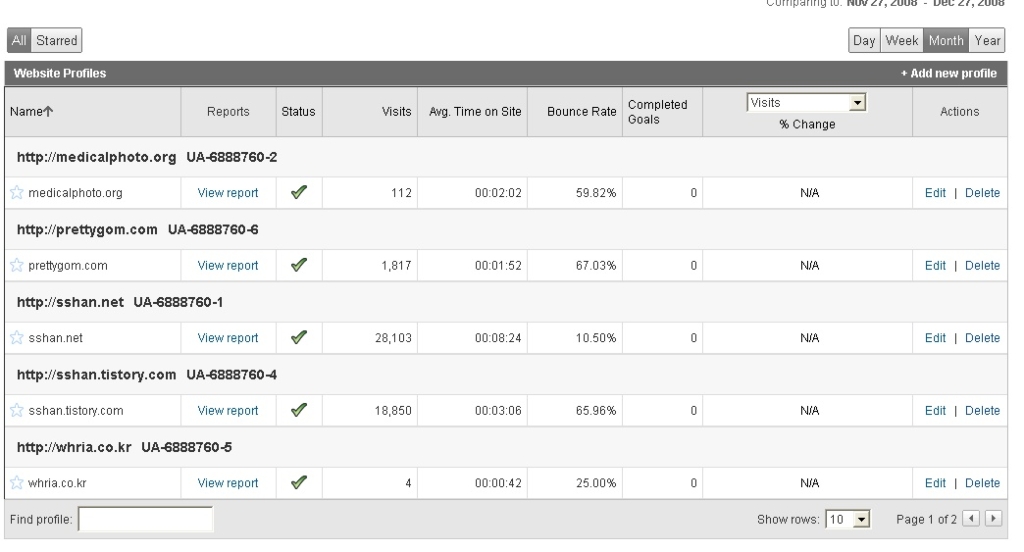
이건 내가 가지고 있는 도메인들이다.여기 안보이는 것까지 합쳐서 6개 의 domain 을 가지고 있다. 이 중에서
http://sshan.net 의 통계를 보자. 참고로
sshan.net 은 경제 관련 싸이트이다. 돈을 많이 벌고 싶다면 와서 열심히 읽으시라. ^^ 컴퓨터만 열심히 해서는 가난한 일꾼으로 끝나는 경우도 많으니까...
요건 첫 화면이다. Dashboard 라고 나오는게 첫 화면이고 여기에는 내가 주로 보고 싶은 지표만 골라 놓고 볼 수 있다. 내가 매일 체크하는 지표는 Visit, Pageview, Bounce Rate, Avg. Time, New Visit 이 정도다.
아마 다른건 다 알겠지만
Bounce rate 이게 몰까요 ??? ㅋㅋ 나도 이게 뭔지 알려고 한참 찾았다.
한마디로 웹페이지 들어왔다가 보지도 않고 그냥 나간 사람의 비율이다. 페이지를 넘겨 보지도 않고 클릭도 안하고 나간 사람의 비율이다. bounce rate 따지는 기준은 회사마다 조금씩 다르지만 기본적으로 들어왔다가 그냥 나가는 사람의 비율을 체크하는 지표이다.
만약에 이효리 로 검색해서 싸이트에 들어갔는데 옥동자 홈페이지가 나왔다 보자. 남자들은 바로 나갈 것이다. 10 명 중에 9명이 바로 창을 닫아버렸다면 bounce rate 는 90% 이다. bounce rate 가 낮아야 좋은 홈페이지다. 블로그는 50% 이상으로 높은 경우가 많은데 대개 그 주제만 보고 나가기 때문에 그렇다. 따라서 블로그 운영하는 사람은 bounce rate 가 너무 낮아도 실망할 필요는 없다.
site 에 들어온 사람이 머문 시간이다. 여기 보면 마지막 날이 11:40 이고 그 다음은 5:50 이다. 전전날 통계가 11분 40초이고 전날 통계는 5분 50초라는 이야기이다. 5분 50초 이상하게 짧다. 전날까지 거의 대부분 11분 정도인데... 이건 버그인 듯 하다. site 시간 뿐 아니라 모든 analytics 의 전날 통계(bounce rate 등등 포함)가 부정확하다. 하지만 하루 지나면 정확하게 바뀐다.
absolute unique visit 라는 것은 중복된 방문 통계를 제외하는 것이다. 브라우저를 새로 열고 홈페이지를 방문하면 방문자 통계가 중복해서 잡힌다. 하지만 absolute unique visit 는 IP 를 확인하기 때문에 정확하다.
Bounce rate 는 아까 설명했는데... 표를 보면 이상하다.. 내 홈페이지는 bounce rate 가 80% 대였다가 갑자기 3~4% 정도로 바닥을 기고 있는 것을 볼 수 있다. 평균은 10.5% 이다.
이건... 내가 analytics 코드를 넣는 위치를 잘 못 넣었기 때문이다. analytics 코드는 웹페이지가 열릴때마다 .. 즉 페이지를 넘길 때마다 다시 load 되는 위치에 넣어야 한다.
요즘 많이 쓰는 원프레임 방식의 웹페이지는 별 문제 없다. 하지만 프레임을 나누는 경우에 클릭할 때마다 analytics 코드가 실행되게 해주어야 한다. 안그러면 analytics 가 잡아내지 못한다. 복잡한 이야기이지만 요즘 쓰는 tistory 나 daum, naver 블로그는 모두 원프레임 방식이다. 원프레임이 뭔지 모르겠다고 ?? 이것까지 설명하려면 너무 글이 길어진다. "홈페이지 프레임" 으로 검색해 보도록 !!
내가 analytics 하고 나서 제일 큰 수확이다. 사용자의 해상도를 알 수 있었다. 의외로 1024 x 768 이 많다. 나만 그런 줄 알았는데 다른 사람의 analytics 분석 결과도 1024 x 768 이 제일 많다.... 따라서 홈페이지를 1280 x 1024 같은 해상도로 최적화 했다가는 1/3 의 독자를 잃는 수가 있다. 웹페이지는 접근성이 중요하다. 나는 이것을 보자마자 sshan.net 을 1024 x 768 에 최적화 시켰다.
explore 를 많이 쓰지만 firefox, chrome, safari, opera 도 많이 쓴다. camino 는 나도 첨 듣는다. 참고로 나도 firefox 를 주로 쓴다. 속도가 예술이다.
아래 사항은 꼭 알아두는 것이 좋다.
- 통계자료는 새벽 0 시에 업데이트 된다. 따라서 오늘 설치했다면 통계는 내일 0 시에 집계될 것이다. 설치 후에 바로 안된다고 불평하지 말자.
- 기본으로 제공하는 javascript 로 설치하면 검색엔진이 전부 "search" 로 나온다. 이는 우리나라 검색엔진 등록이 안되있는 문제이다. 이 문제를 해결하려면 내가 작성한 글을 보시라. 50 군데 영문싸이트를 돌아다니면서 내린 최종 결론이며 잘 동작한다.
http://prettygom.com/entry/Google-Analytics-에-검색엔진-추가하기
- analytics 결과는 전날 데이터가 몇몇 데이터(bounce rate, visit ... )가 부정확하다. 하루 지나면 교정이 된다.
- analytics 코드는 페이지를 넘길 때마다 실행되는 위치에 넣어야 된다. 그래야 analytics 가 페이지를 넘겼는지... 이사람이 나갔는지.. 멍하고 있는지 등등을 알 수 있다.
오늘도 바빠 죽겠는데 길게 썼다. 이건 취미 생활인데... ㅋㅋ 하여튼 구글은 대단한 회사이다.
구글은 여러가지 다른 선물도 주고 있다.
google reader
google office
google memo
google earth
google gmail
이중에 안쓰는 것 있으면 써보길 바란다. 감탄이 절로 나올 것이다.
















 토론 2 옆에 보면 아까 보여드린
토론 2 옆에 보면 아까 보여드린 



